Strings are well-known data types and you can do all sorts of things.
Combining Strings.
Example: I'm going to combine two string value of street + word.
>>> street = "Roger Street"
>>> word = " I live on "
>>> word + street
' I live on Roger Street'
What else can you do with Strings?
All sorts of stuff really, take a look at the built-in method.
dir() can be used on any Python objects.
>>> dir(str)
['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isascii', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
>>> dir(word)
['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isascii', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
help() is another useful tool. In order to use the built in help feature you will have to pass in the object or variable.
Example:
>>> help(str)
Help on class str in module builtins:
class str(object)
| str(object='') -> str
| str(bytes_or_buffer[, encoding[, errors]]) -> str
|
| Create a new string object from the given object. If encoding or
| errors is specified, then the object must expose a data buffer
| that will be decoded using the given encoding and error handler.
| Otherwise, returns the result of object.__str__() (if defined)
| or repr(object).
| encoding defaults to sys.getdefaultencoding().
| errors defaults to 'strict'.
|
| Methods defined here:
|
| __add__(self, value, /)
| Return self+value.
|
| __contains__(self, key, /)
| Return key in self.
|
| __eq__(self, value, /)
| Return self==value.
|
| __format__(self, format_spec, /)
| Return a formatted version of the string as described by format_spec.
|
| __ge__(self, value, /)
| Return self>=value.
|
| __getattribute__(self, name, /)
| Return getattr(self, name).
|
| __getitem__(self, key, /)
| Return self[key].
|
| __getnewargs__(...)
|
| __gt__(self, value, /)
| Return self>value.
|
| __hash__(self, /)
| Return hash(self).
|
| __iter__(self, /)
| Implement iter(self).
|
| __le__(self, value, /)
| Return self<=value.
|
| __len__(self, /)
| Return len(self).
|
| __lt__(self, value, /)
| Return self<value.
|
| __mod__(self, value, /)
| Return self%value.
|
| __mul__(self, value, /)
| Return self*value.
|
| __ne__(self, value, /)
| Return self!=value.
|
| __repr__(self, /)
| Return repr(self).
|
| __rmod__(self, value, /)
| Return value%self.
|
| __rmul__(self, value, /)
| Return value*self.
|
| __sizeof__(self, /)
| Return the size of the string in memory, in bytes.
|
| __str__(self, /)
| Return str(self).
|
| capitalize(self, /)
| Return a capitalized version of the string.
|
| More specifically, make the first character have upper case and the rest lower
| case.
|
| casefold(self, /)
| Return a version of the string suitable for caseless comparisons.
|
| center(self, width, fillchar=' ', /)
| Return a centered string of length width.
|
| Padding is done using the specified fill character (default is a space).
|
| count(...)
| S.count(sub[, start[, end]]) -> int
|
| Return the number of non-overlapping occurrences of substring sub in
| string S[start:end]. Optional arguments start and end are
| interpreted as in slice notation.
|
| encode(self, /, encoding='utf-8', errors='strict')
| Encode the string using the codec registered for encoding.
|
| encoding
| The encoding in which to encode the string.
| errors
| The error handling scheme to use for encoding errors.
| The default is 'strict' meaning that encoding errors raise a
| UnicodeEncodeError. Other possible values are 'ignore', 'replace' and
| 'xmlcharrefreplace' as well as any other name registered with
| codecs.register_error that can handle UnicodeEncodeErrors.
|
| endswith(...)
| S.endswith(suffix[, start[, end]]) -> bool
|
| Return True if S ends with the specified suffix, False otherwise.
| With optional start, test S beginning at that position.
| With optional end, stop comparing S at that position.
| suffix can also be a tuple of strings to try.
|
| expandtabs(self, /, tabsize=8)
| Return a copy where all tab characters are expanded using spaces.
|
| If tabsize is not given, a tab size of 8 characters is assumed.
|
| find(...)
| S.find(sub[, start[, end]]) -> int
|
| Return the lowest index in S where substring sub is found,
| such that sub is contained within S[start:end]. Optional
| arguments start and end are interpreted as in slice notation.
|
| Return -1 on failure.
|
| format(...)
| S.format(*args, **kwargs) -> str
|
| Return a formatted version of S, using substitutions from args and kwargs.
| The substitutions are identified by braces ('{' and '}').
|
| format_map(...)
| S.format_map(mapping) -> str
|
| Return a formatted version of S, using substitutions from mapping.
| The substitutions are identified by braces ('{' and '}').
|
| index(...)
| S.index(sub[, start[, end]]) -> int
|
| Return the lowest index in S where substring sub is found,
| such that sub is contained within S[start:end]. Optional
| arguments start and end are interpreted as in slice notation.
|
| Raises ValueError when the substring is not found.
|
| isalnum(self, /)
| Return True if the string is an alpha-numeric string, False otherwise.
|
| A string is alpha-numeric if all characters in the string are alpha-numeric and
| there is at least one character in the string.
|
| isalpha(self, /)
| Return True if the string is an alphabetic string, False otherwise.
|
| A string is alphabetic if all characters in the string are alphabetic and there
| is at least one character in the string.
|
| isascii(self, /)
| Return True if all characters in the string are ASCII, False otherwise.
|
| ASCII characters have code points in the range U+0000-U+007F.
| Empty string is ASCII too.
|
| isdecimal(self, /)
| Return True if the string is a decimal string, False otherwise.
|
| A string is a decimal string if all characters in the string are decimal and
| there is at least one character in the string.
|
| isdigit(self, /)
| Return True if the string is a digit string, False otherwise.
|
| A string is a digit string if all characters in the string are digits and there
| is at least one character in the string.
|
| isidentifier(self, /)
| Return True if the string is a valid Python identifier, False otherwise.
|
| Use keyword.iskeyword() to test for reserved identifiers such as "def" and
| "class".
|
| islower(self, /)
| Return True if the string is a lowercase string, False otherwise.
|
| A string is lowercase if all cased characters in the string are lowercase and
| there is at least one cased character in the string.
|
| isnumeric(self, /)
| Return True if the string is a numeric string, False otherwise.
|
| A string is numeric if all characters in the string are numeric and there is at
| least one character in the string.
|
| isprintable(self, /)
| Return True if the string is printable, False otherwise.
|
| A string is printable if all of its characters are considered printable in
| repr() or if it is empty.
|
| isspace(self, /)
| Return True if the string is a whitespace string, False otherwise.
|
| A string is whitespace if all characters in the string are whitespace and there
| is at least one character in the string.
|
| istitle(self, /)
| Return True if the string is a title-cased string, False otherwise.
|
| In a title-cased string, upper- and title-case characters may only
| follow uncased characters and lowercase characters only cased ones.
|
| isupper(self, /)
| Return True if the string is an uppercase string, False otherwise.
|
| A string is uppercase if all cased characters in the string are uppercase and
| there is at least one cased character in the string.
|
| join(self, iterable, /)
| Concatenate any number of strings.
|
| The string whose method is called is inserted in between each given string.
| The result is returned as a new string.
|
| Example: '.'.join(['ab', 'pq', 'rs']) -> 'ab.pq.rs'
|
| ljust(self, width, fillchar=' ', /)
| Return a left-justified string of length width.
|
| Padding is done using the specified fill character (default is a space).
|
| lower(self, /)
| Return a copy of the string converted to lowercase.
|
| lstrip(self, chars=None, /)
| Return a copy of the string with leading whitespace removed.
|
| If chars is given and not None, remove characters in chars instead.
|
| partition(self, sep, /)
| Partition the string into three parts using the given separator.
|
| This will search for the separator in the string. If the separator is found,
| returns a 3-tuple containing the part before the separator, the separator
| itself, and the part after it.
|
| If the separator is not found, returns a 3-tuple containing the original string
| and two empty strings.
|
| replace(self, old, new, count=-1, /)
| Return a copy with all occurrences of substring old replaced by new.
|
| count
| Maximum number of occurrences to replace.
| -1 (the default value) means replace all occurrences.
|
| If the optional argument count is given, only the first count occurrences are
| replaced.
|
| rfind(...)
| S.rfind(sub[, start[, end]]) -> int
|
| Return the highest index in S where substring sub is found,
| such that sub is contained within S[start:end]. Optional
| arguments start and end are interpreted as in slice notation.
|
| Return -1 on failure.
|
| rindex(...)
| S.rindex(sub[, start[, end]]) -> int
|
| Return the highest index in S where substring sub is found,
| such that sub is contained within S[start:end]. Optional
| arguments start and end are interpreted as in slice notation.
|
| Raises ValueError when the substring is not found.
|
| rjust(self, width, fillchar=' ', /)
| Return a right-justified string of length width.
|
| Padding is done using the specified fill character (default is a space).
|
| rpartition(self, sep, /)
| Partition the string into three parts using the given separator.
|
| This will search for the separator in the string, starting at the end. If
| the separator is found, returns a 3-tuple containing the part before the
| separator, the separator itself, and the part after it.
|
| If the separator is not found, returns a 3-tuple containing two empty strings
| and the original string.
|
| rsplit(self, /, sep=None, maxsplit=-1)
| Return a list of the words in the string, using sep as the delimiter string.
|
| sep
| The delimiter according which to split the string.
| None (the default value) means split according to any whitespace,
| and discard empty strings from the result.
| maxsplit
| Maximum number of splits to do.
| -1 (the default value) means no limit.
|
| Splits are done starting at the end of the string and working to the front.
|
| rstrip(self, chars=None, /)
| Return a copy of the string with trailing whitespace removed.
|
| If chars is given and not None, remove characters in chars instead.
|
| split(self, /, sep=None, maxsplit=-1)
| Return a list of the words in the string, using sep as the delimiter string.
|
| sep
| The delimiter according which to split the string.
| None (the default value) means split according to any whitespace,
| and discard empty strings from the result.
| maxsplit
| Maximum number of splits to do.
| -1 (the default value) means no limit.
|
| splitlines(self, /, keepends=False)
| Return a list of the lines in the string, breaking at line boundaries.
|
| Line breaks are not included in the resulting list unless keepends is given and
| true.
|
| startswith(...)
| S.startswith(prefix[, start[, end]]) -> bool
|
| Return True if S starts with the specified prefix, False otherwise.
| With optional start, test S beginning at that position.
| With optional end, stop comparing S at that position.
| prefix can also be a tuple of strings to try.
|
| strip(self, chars=None, /)
| Return a copy of the string with leading and trailing whitespace remove.
|
| If chars is given and not None, remove characters in chars instead.
|
| swapcase(self, /)
| Convert uppercase characters to lowercase and lowercase characters to uppercase.
|
| title(self, /)
| Return a version of the string where each word is titlecased.
|
| More specifically, words start with uppercased characters and all remaining
| cased characters have lower case.
|
| translate(self, table, /)
| Replace each character in the string using the given translation table.
|
| table
| Translation table, which must be a mapping of Unicode ordinals to
| Unicode ordinals, strings, or None.
|
| The table must implement lookup/indexing via __getitem__, for instance a
| dictionary or list. If this operation raises LookupError, the character is
| left untouched. Characters mapped to None are deleted.
|
| upper(self, /)
| Return a copy of the string converted to uppercase.
|
| zfill(self, width, /)
| Pad a numeric string with zeros on the left, to fill a field of the given width.
|
| The string is never truncated.
|
| ----------------------------------------------------------------------
| Static methods defined here:
|
| __new__(*args, **kwargs) from builtins.type
| Create and return a new object. See help(type) for accurate signature.
|
| maketrans(x, y=None, z=None, /)
| Return a translation table usable for str.translate().
|
| If there is only one argument, it must be a dictionary mapping Unicode
| ordinals (integers) or characters to Unicode ordinals, strings or None.
| Character keys will be then converted to ordinals.
| If there are two arguments, they must be strings of equal length, and
| in the resulting dictionary, each character in x will be mapped to the
| character at the same position in y. If there is a third argument, it
| must be a string, whose characters will be mapped to None in the result.
>>>
>>> help(str.upper )
Help on method_descriptor:
upper(self, /)
Return a copy of the string converted to uppercase.
OR
>>> help(word.upper )
Help on built-in function upper:
upper() method of builtins.str instance
Return a copy of the string converted to uppercase.
Example of using upper/lower.
Let's go back to the value street. I created Street value as "Roger Street".
>>> street
'Roger Street'
>>> street.lower()
'roger street'
>>> street.upper()
'ROGER STREET'
Can you see what the lower and upper function just did to the variable Street?
It converted the full string to lower and upper.
If we go back and print(street) what value do you think it will send back?
>>> print(street)
Roger Street
>>>
It will spit back the original street variable.
If say you wanted to cover the original street value to lower and keep it that way. You can send it to a new or existing variable.
Examples:
>>> street
'Roger Street'
>>> street_lower=street.lower()
>>> print(street_lower)
roger street
What about using startswith() and endwith() methods.
>>> myname="John.Smith"
>>> myname
'John.Smith'
>>> myname.startswith("Jo")
True
>>> myname.endswith("th")
True
So using these method we can tell it return a Boolean value.
Boolean values is either True or False .
What about combining methods? Yes, you can do this.
Take a look as we combine the lower and startswith methods together.
>>> myname.lower().startswith("jo")
True
>>> myname.lower().startswith("Jo")
False
Saturday, November 3, 2018
Tuesday, October 30, 2018
Python Data Types.
Python has various different data types.
Let's take a look at some of them.
1. Strings (str): This could be any character surround via by a single or double quote. state = "California"
2. Integer (int): zip=92129
3. Float (float): latitude=34.073620
4. Boolean (bool): True or false You_Rich=True
5. List (list): Value can be of any data type in a []. home =["Beverly Hills", "Mansion", "Penthouse"]
6. Dictionary list of key value pairs in a {}. phone_contact ={"John": "555-5555", "Gina": "555-5252", "Lisa": "555-5255"}
7. Set (set): Collection of unique elements. set(vendors)=>['att', 'verizon', 'tcox']
8 Tuple: (tuple) Immutable sequence of values (): address=(10, 10, 20, 20)
Immutable in python = You can't change the value.
Other types such as Strings, List, Dictionary are all mutable. You can change these values .
Example of immutable values such as social security #. You are assigned one social security #. That value will never change. You can change your name but your SSN will be the same.
Determining types.
type(name of variable)
Example:
>>> state = "California"
>>> type(state)
<class 'str'>
>>> type(zip)
<class 'int'>
>>> type(latitude)
<class 'float'>
Python operators


Let's take a look at some of them.
1. Strings (str): This could be any character surround via by a single or double quote. state = "California"
2. Integer (int): zip=92129
3. Float (float): latitude=34.073620
4. Boolean (bool): True or false You_Rich=True
5. List (list): Value can be of any data type in a []. home =["Beverly Hills", "Mansion", "Penthouse"]
6. Dictionary list of key value pairs in a {}. phone_contact ={"John": "555-5555", "Gina": "555-5252", "Lisa": "555-5255"}
7. Set (set): Collection of unique elements. set(vendors)=>['att', 'verizon', 'tcox']
8 Tuple: (tuple) Immutable sequence of values (): address=(10, 10, 20, 20)
Immutable in python = You can't change the value.
Other types such as Strings, List, Dictionary are all mutable. You can change these values .
Example of immutable values such as social security #. You are assigned one social security #. That value will never change. You can change your name but your SSN will be the same.
Determining types.
type(name of variable)
Example:
>>> state = "California"
>>> type(state)
<class 'str'>
>>> type(zip)
<class 'int'>
>>> type(latitude)
<class 'float'>
Python operators
Python has the different operators which allows you to carry out required calculations in your program.

+ , - and * works as expected, remaining operators require some explanation.
similarly you can use - , % , // , / , * , ** with assignment operator to form augmented assignment operator.

Source: https://thepythonguru.com/python-numbers/
Great Video to watch regarding Data Types.
Sunday, October 28, 2018
Python Basic Variables
Basic Variables in Python.
What is a Variable? It's a value you assign in python code to reference a value to a variable.
Take a look at the sample below.
Examples below.
Examples:
>>> hostname = 'home1'
>>> print(hostname)
home1
## This example above assign home1 to the variable hostname.
>>> pi = 3.14159
>>> print(pi)
3.14159
## This example above assign 3.14159 to variable name pi.
>>> banner = "\n\n Welcome home master! \n\n"
>>> print(banner)
Welcome home master!
>>>
## The example above assign Welcome home master! to the variable banner.
Using print interprets the "\n" and a new line is print statement only not within the Python terminal.
>>> banner
'\n\n Welcome home master! \n\n'
>>>
See the different above. If you call banner it will spit out the actual \n value from the variable banner.
Stick with either single quote or double quote. You can not mix and match them when you assign variables.
Example:
hostname = 'home1"
OR
hostname ="home1'
>>> hostname = 'home1"
SyntaxError: EOL while scanning string literal
>>>
Python doesn't like it when you use it together in the same line.
Stick with a single quote or a double quote.
Other site with good reference on Variables:
http://interactivepython.org/runestone/static/CS152f17/SimplePythonData/Variables.html
CJ Dojo has a nice intro video take a look.
What is a Variable? It's a value you assign in python code to reference a value to a variable.
Take a look at the sample below.
Examples below.
Examples:
>>> hostname = 'home1'
>>> print(hostname)
home1
## This example above assign home1 to the variable hostname.
>>> pi = 3.14159
>>> print(pi)
3.14159
## This example above assign 3.14159 to variable name pi.
>>> banner = "\n\n Welcome home master! \n\n"
>>> print(banner)
Welcome home master!
>>>
## The example above assign Welcome home master! to the variable banner.
Using print interprets the "\n" and a new line is print statement only not within the Python terminal.
>>> banner
'\n\n Welcome home master! \n\n'
>>>
See the different above. If you call banner it will spit out the actual \n value from the variable banner.
Stick with either single quote or double quote. You can not mix and match them when you assign variables.
Example:
hostname = 'home1"
OR
hostname ="home1'
>>> hostname = 'home1"
SyntaxError: EOL while scanning string literal
>>>
Python doesn't like it when you use it together in the same line.
Stick with a single quote or a double quote.
Other site with good reference on Variables:
http://interactivepython.org/runestone/static/CS152f17/SimplePythonData/Variables.html
CJ Dojo has a nice intro video take a look.
Learning Python and installing it on windows.
I'm on a mission to learn Python!! Just my daily log so I can keep my self motivate to learn python coding and keep at it.
Why do I want to learn python?
So I can automate the boring stuff and learn something new!
What version am I going to learn?
Python 3.
Installation:
Download Python from offical website.
https://www.python.org/downloads/
Since I don't have another PC I will install it on my existing windows machine.
Setup the Window System variable.
https://docs.python.org/3/using/windows.html
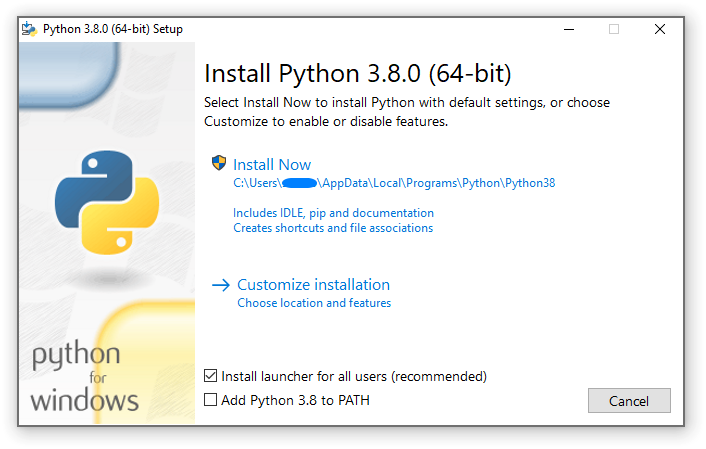
Why do I want to learn python?
So I can automate the boring stuff and learn something new!
What version am I going to learn?
Python 3.
Installation:
Download Python from offical website.
https://www.python.org/downloads/
Since I don't have another PC I will install it on my existing windows machine.
Setup the Window System variable.
https://docs.python.org/3/using/windows.html
3.1.2. Installation Steps
Four Python 3.7 installers are available for download - two each for the 32-bit and 64-bit versions of the interpreter. The web installer is a small initial download, and it will automatically download the required components as necessary. The offline installer includes the components necessary for a default installation and only requires an internet connection for optional features. See Installing Without Downloading for other ways to avoid downloading during installation.
After starting the installer, one of two options may be selected:
If you select “Install Now”:
- You will not need to be an administrator (unless a system update for the C Runtime Library is required or you install the Python Launcher for Windows for all users)
- Python will be installed into your user directory
- The Python Launcher for Windows will be installed according to the option at the bottom of the first page
- The standard library, test suite, launcher and pip will be installed
- If selected, the install directory will be added to your
PATH - Shortcuts will only be visible for the current user
Selecting “Customize installation” will allow you to select the features to install, the installation location and other options or post-install actions. To install debugging symbols or binaries, you will need to use this option.
To perform an all-users installation, you should select “Customize installation”. In this case:
- You may be required to provide administrative credentials or approval
- Python will be installed into the Program Files directory
- The Python Launcher for Windows will be installed into the Windows directory
- Optional features may be selected during installation
- The standard library can be pre-compiled to bytecode
- If selected, the install directory will be added to the system
PATH - Shortcuts are available for all users
Subscribe to:
Comments (Atom)